Several visualization classes were created specifically for the support of water column data. These exports are generated by the FMMidwater module for display and analysis in Fledermaus.
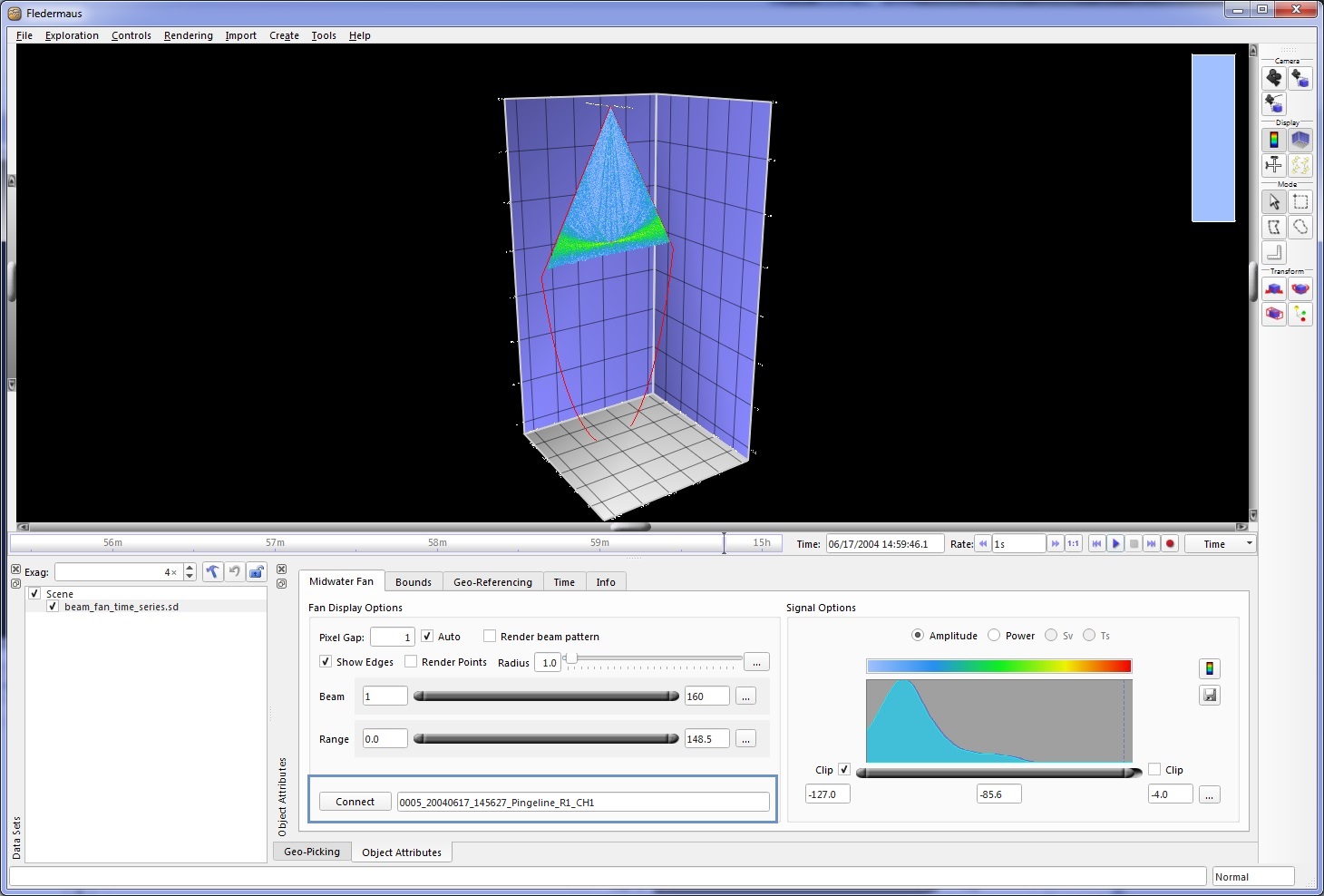
Beam Fan Time Series Object
The Beam Fan Time Series SD object is a 4D visualization of the water column swath data. Once exported, the SD object can be loaded into Fledermaus. The appearance of the object is shown in the Beam Fan SD Object figure below. This object is 'time aware' in that as the time line is moved in Fledermaus, the Beam Fan object will move through the scene. This object is also know as a 'dynamic dependence' object in that it is dependent on and references a specific GWC file and updates its appearance by loading data from the GWC appropriate to the current time indicated by the Fledermaus time bar. This is different from most SD objects that are 'self-contained' in that the SD file has all data necessary for display within the visualization.
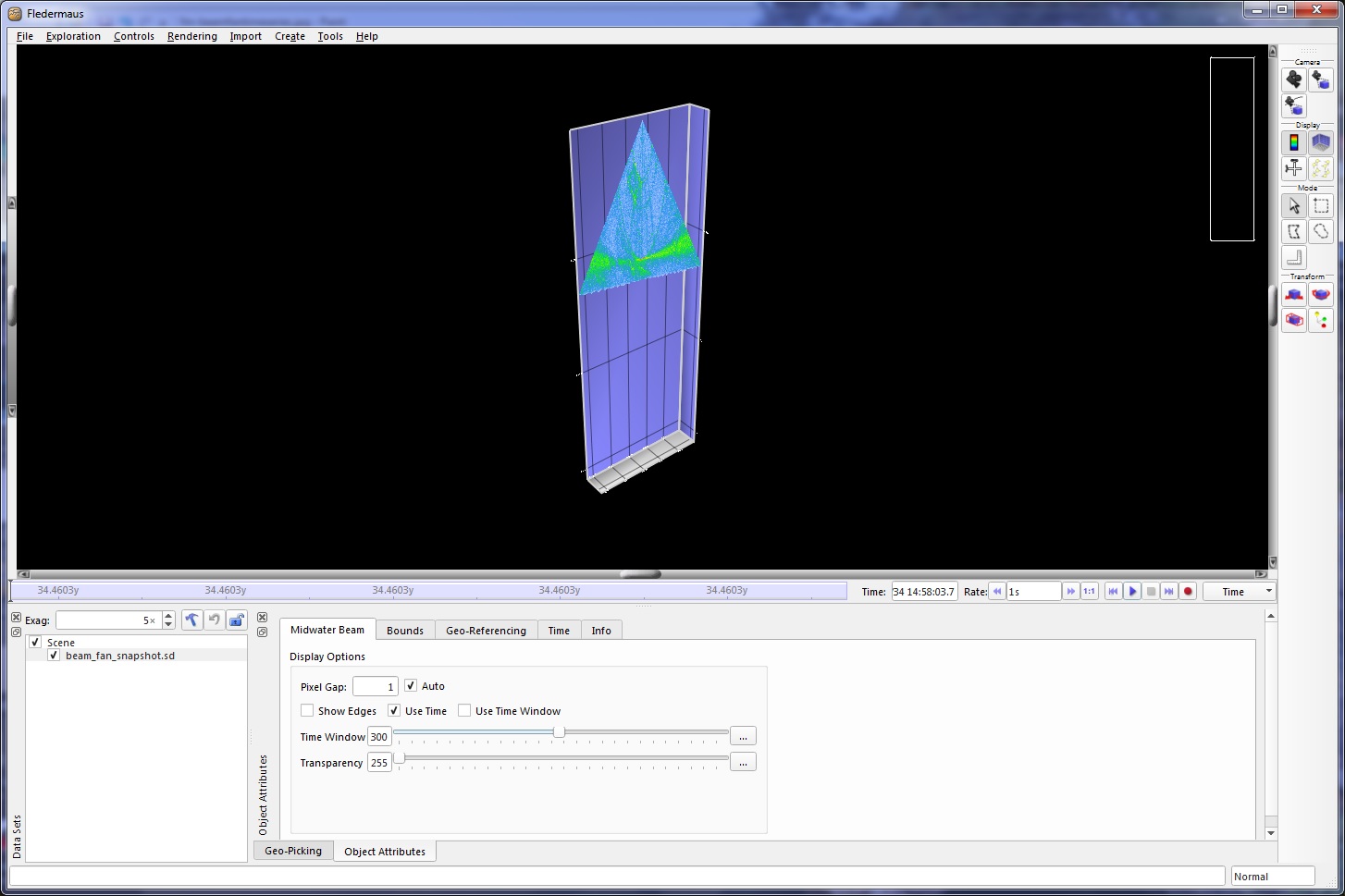
Beam Fan Snapshot Object
The Beam Fan Snapshot SD object is a 3D visualization of the water column swath data for a single ping.
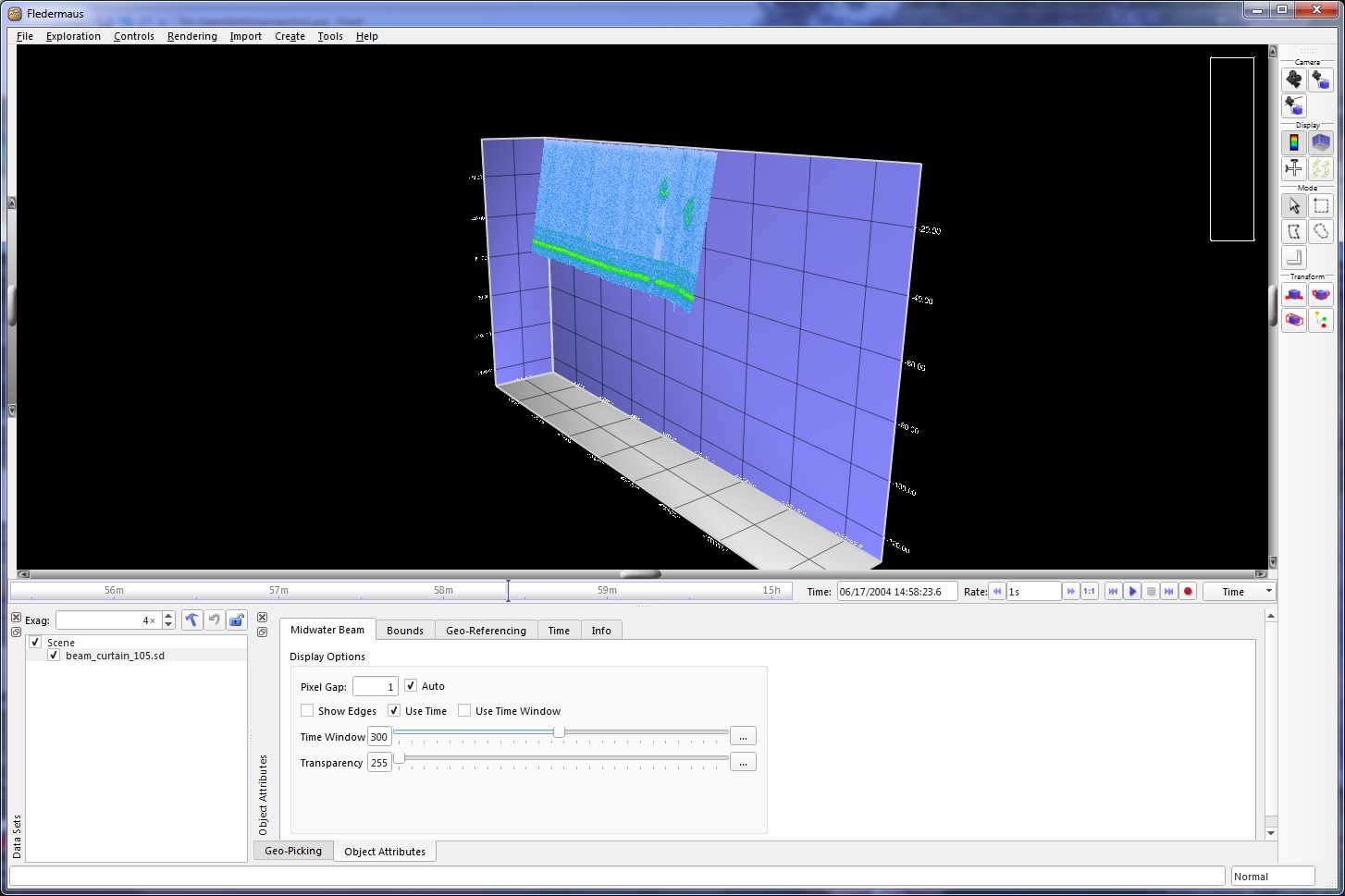
Beam Curtain Object
The Beam Curtain SD object is a 4D visual representation of a single beam from the entire GWC file and is shown in conjunction with a Beam Fan object in the Beam Line SD Object figure below. It is similar to a Vertical Curtain in that it contains imagery data with the addition of being aligned to the beam angle at each point in time. It is also 'time aware' so it grows as the time bar is moved within Fledermaus.
A simple way to export this object is to use the Beam option from the Beam View Options panel (Beam View Options figure below) and select the desired beam number. One could then zoom in to a specific feature, threshold out the ambient noise and proceed directly to exporting of the Beam Line.
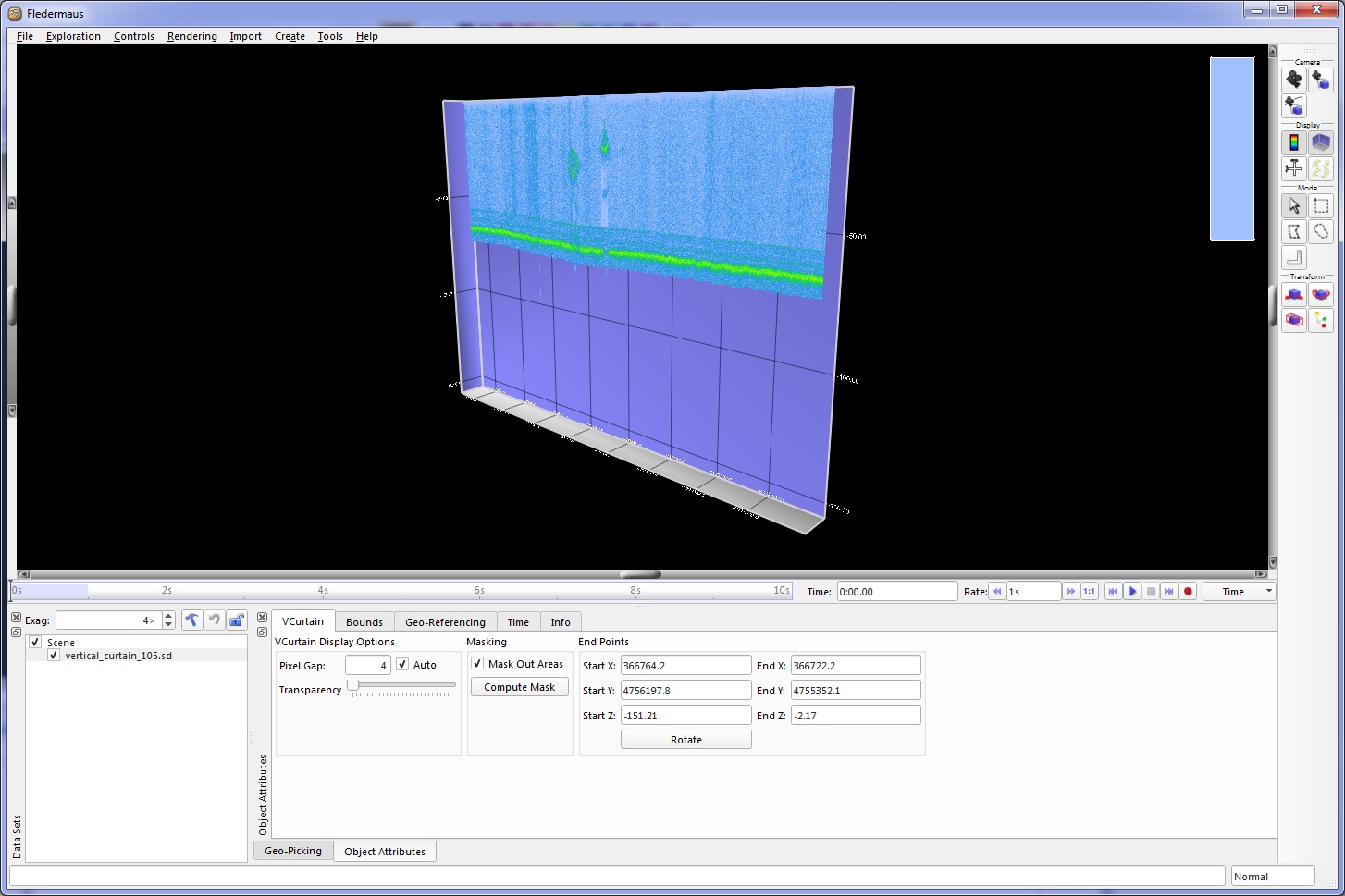
Vertical Curtain Object
The VerticalCurtain SD object is a 4D visual representation of a single vertical beam from the entire GWC file. This is typically used for seismic data.
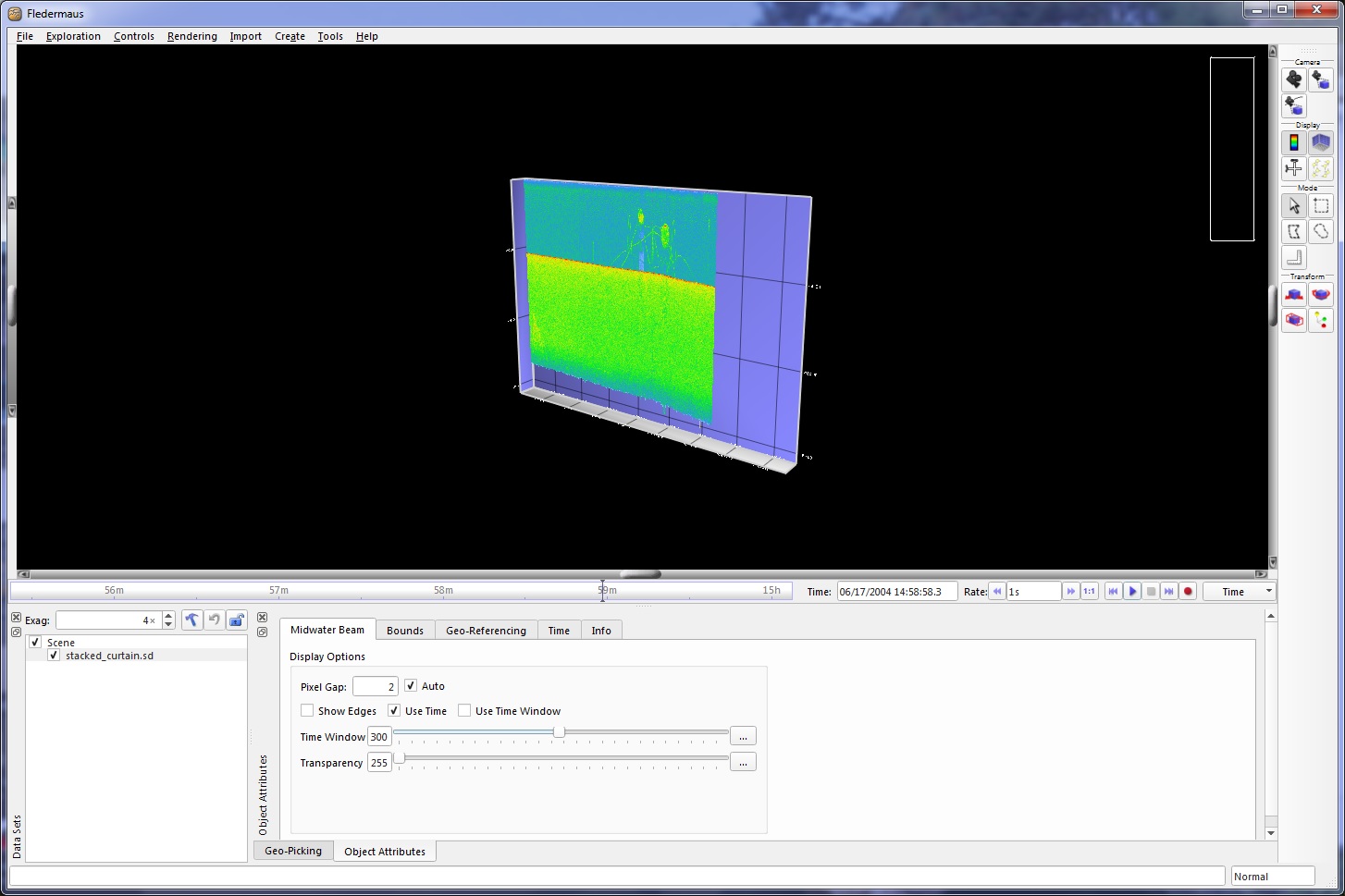
Stacked Curtain Object
The StackedCurtain SD object is a 4D visual representation of the stacked view of the water column data. This can be useful as a backdrop in the scene with other exported data.
Point Object
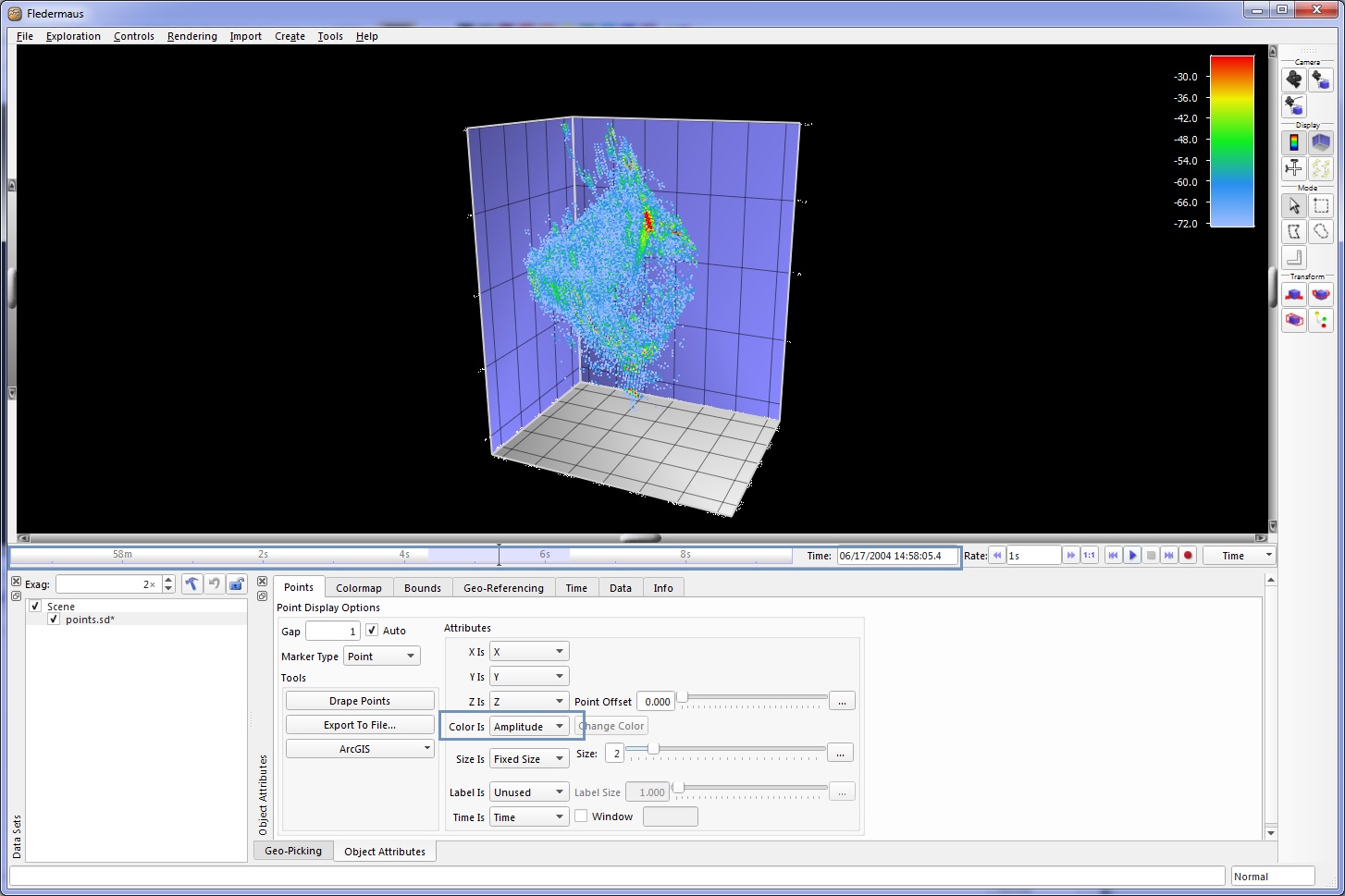
The Point Object is a 4D visualization representation of the bore site (acoustic axis of a directional sonar beam) positions of the filtered samples. Each point can be attributed with signal level, time, ping and beam so that you can use Fledermaus to change colors based on any of these attributes, including depth. When this object is exported with time, it is 'time aware' and grows according to the current time bar position as shown in the Points SD Object figure below.
Point Cluster Object
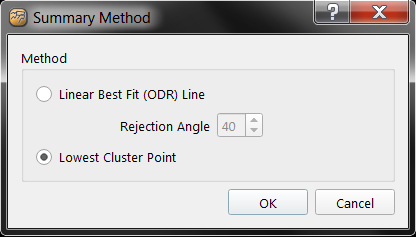
The Point Clusters SD object is a special Fledermaus object type that was created for analyzing and characterizing seafloor seeps. Like the Point Object, The Point Cluster Object is a 4D visualization representation of the bore site (acoustic axis of a directional sonar beam) positions of the filtered samples. However, the Point Cluster Object has additional analysis functionality available once the file is loaded in to Fledermaus which allows users to run a clustering algorithm in an attempt to determine collections of sample points that may represent seeps. Options are provided to color by the cluster ID, size of the cluster, and whether or not it is considered a cluster based on given criterion. Basic cluster editing tools that allow the user to select clusters and delete those which are not of interest are included along with several tools to select and reject points that are not of interest. Once the point clusters are edited a cluster summary object can be created. Two algorithms are available for this operation which estimates the point of origin for each seep on the seafloor. The first method, which picks the the lowest point in the seep and projects it onto the seafloor is the default.
A second method, the Linear Best Fit (ODR) Line, attempts to fit a line through the seep data points then project along that line onto the surface selected. When a line for a seep is at an angle from vertical greater than the Rejection Angle, the operation will be skipped for that seep and no point on the surface will be generated. Such lines will be depicted in the scene in red. Lines that are sufficiently vertical (less than the Rejection Angle) will be depicted in white. The lines are not required and may be removed after the operation if desired. The default maximum angle from vertical is 40 degrees. The limit may be changed as desired. If the best fit line does not extend to the surface (e.g. it extends past the surface or a hole exists in the surface where the intersection of the line and surface would otherwise be), then no intersection point will be generated and the line will be depicted in red. The algorithm used generates the 3D Orthogonal Distance Regression (ODR) line. The algorithm uses the SVD (singular value decomposition) to determine a vector for the line. Briefly, the method first determines the mean (or centroid) of the points in the seep, the mean is subtracted from each of the points, then the SVD routine is executed using this data and the vector retrieved from the result. The angle of the vector from vertical is determined and if it is within the Rejection Angle, the vector is sampled from the centroid until it touches the surface or exceeds the bounds of the surface. The summary object then adds the position at point of intersection, if one exists. This method can fail if the seep is ill-defined or has a lot of curvature (e.g. the top is caught in current). The image below shows a sample of a set of clusters with the ODR line shown.
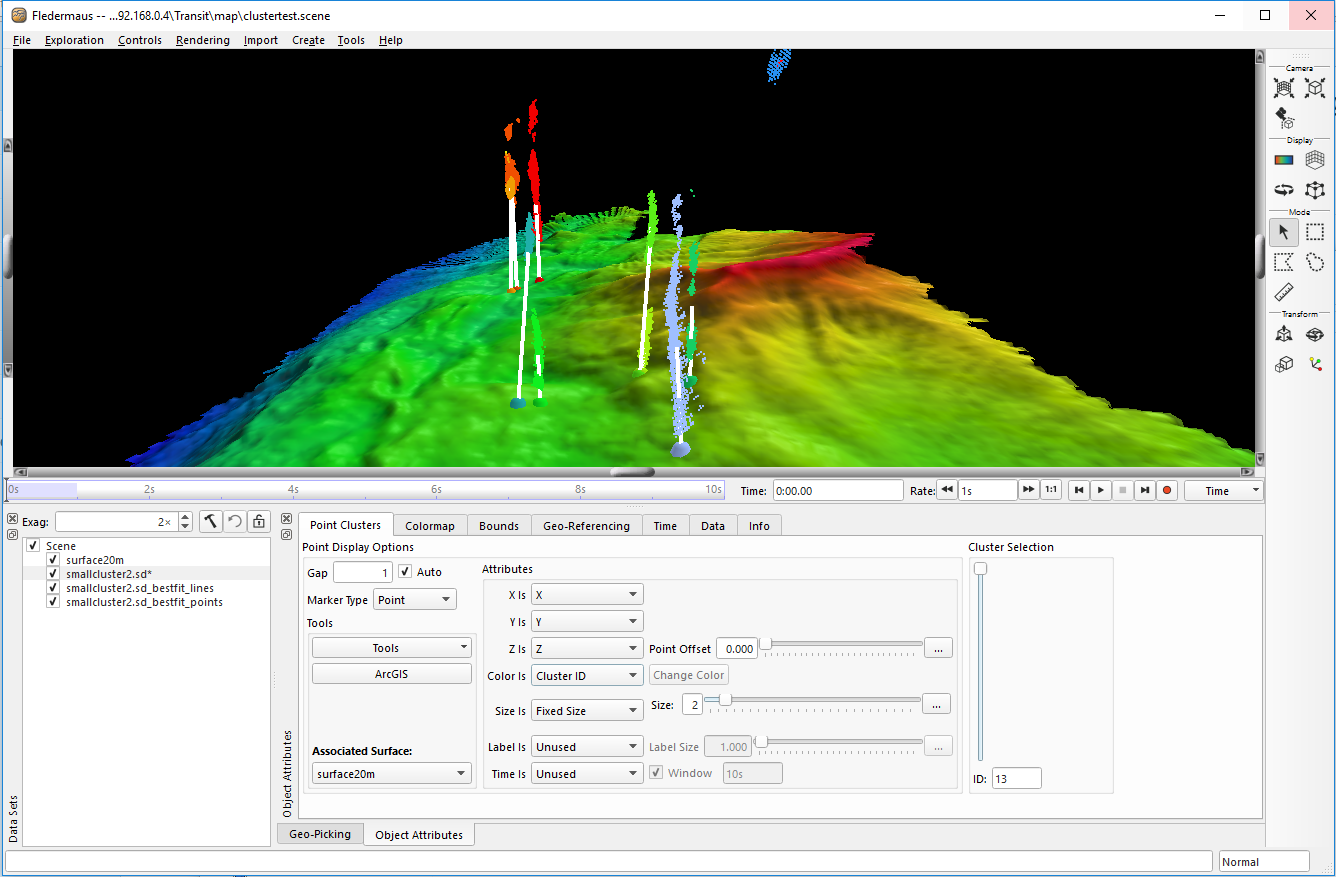
Data used in this section is courtesy of the University of New Hampshire Center for Coastal and Ocean Mapping / Joint Hydrographic Center and NOAA Office of Exploration and Research. This image below gives a example of a point cluster object in use.
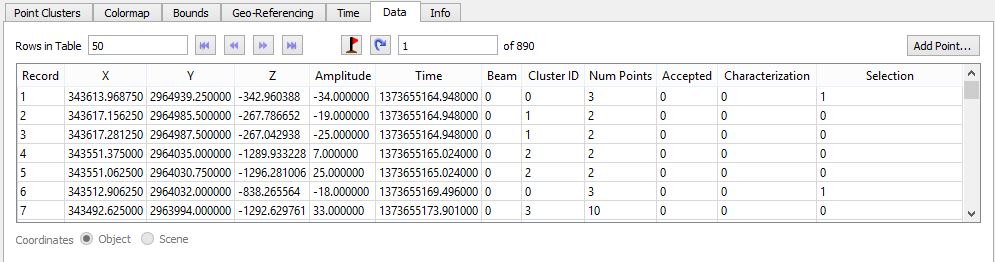
The attribute panel of the Point Cluster Object, shown below contains the set of fields stored for each point in the cluster object. They include the X, Y, and Z coordinate, an amplitude value, a time field, and a beam value. These fields come from the collected data. In addition there are cluster ID, number of points, accepted, characterization, and selection fields. This fields are filled in by running the tools to perform clustering operations on the data. In a similar fashion to the data tab for point and line objects you can examine all the data in a spreadsheet like view, locate points with the locator (flag button), and manually edit and add points if appropriate.
When a clustering operation is done, points are given a Cluster ID. All points in the same cluster will have the same ID. Cluster ID #0 is a special ID for any points that did not find at least one other point in a cluster. The reason they are given this special ID is it make it easier to then delete these points if the user chooses. The Num Points field indicates how many points in total share that points cluster ID. The Accepted field will be either 0 or 1 and is used as a working field to indicate if the user feels that a given cluster is meaningful. The filter tools set this field and it can be used in conjunction with an editing tool to easy remove points the are not accepted. Characterization is not used yet although the intention is to add some feature type detection tools in an upcoming version. The Selection field is an internal field that supports using a slider to select and visually highlight specific clusters and is described in more detail below.
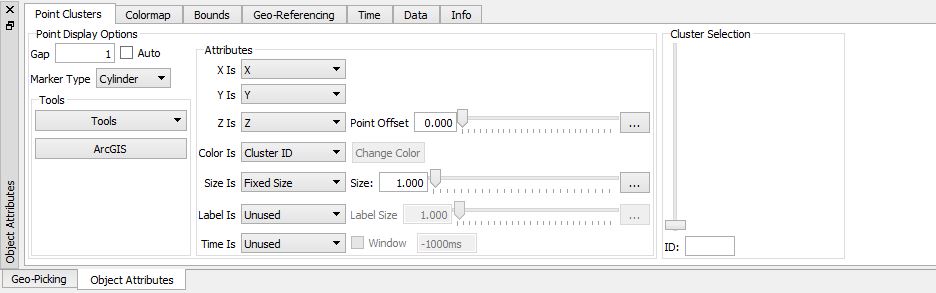
The main panel is nearly identical to the regular 3D point class although it contains a specific set of attributes and there are a number of additional tools that perform cluster specific operations.
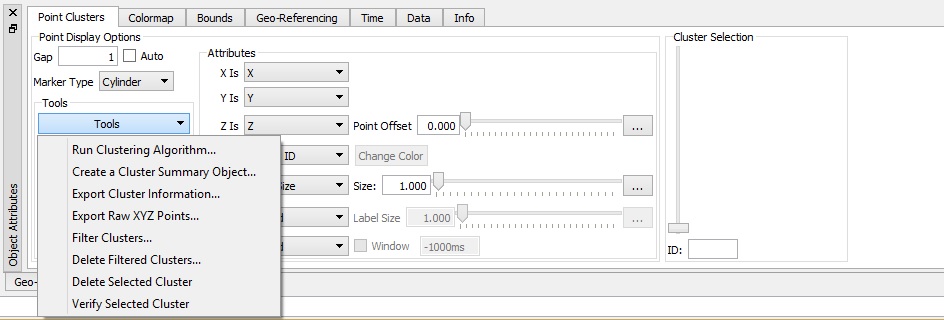
An additional cluster selection slider is available on the right hand side. Any of the fields described above can be used to color the point data. When the Color Is field is set to "Selection" this slider will visually highlight in the main view all the points that match the selected cluster ID's. Normally when a cluster object is first loaded/built, no analysis has yet been done. When sliding through clusters you can easily remove the highlighted cluster by using the "d" key as a short cut for deleting the selected cluster. The Tools menu provides access to analysis tools.
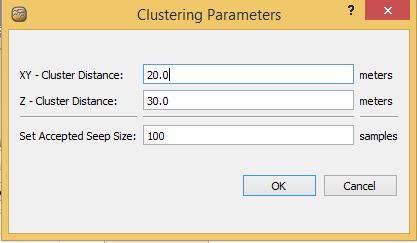
The main tool is the Run Clustering Algorithm option. This will ask for some cluster parameters including a horizontal (xy) distance, a vertical (z) distance, and an accepted seep size.
The algorithm takes each point and looks at every other point and finds any points that a both less than the horizontal and vertical distance away. Any matching points found now create a cluster. Then any of the new points that have joined the cluster are similarly tested and the cluster will grow until no more points match the given criterion. Once this happens the algorithm moves onto the next un-clustered point and tries grouping it, and so on until all points in the data set have been clustered. The cluster ID's go from 1 to the number of clusters found. Cluster ID #0 is reserved and assigned to any singular points that did not find any companion points. This is done to make it easy to remove these singular points from the data set. The algorithm will fill in the Cluster ID, Num Points, and Accepted fields. The "Set Accepted Seep Size" value is used to determine if the Accepted field should be set to 1 or not. If the number of points in a given cluster matches or exceeds this value then each point in that cluster will have its value set. You can run this algorithm as many times as desired, although each time it is run new results will be written into the fields as described above.
Points colored by Cluster ID; the points are amalgamated into clusters based on the parameters set for the Clustering Algorithm.
In the image above, you can see there are multiple clusters identified (indicated by different colors) in each vertical point cloud representing a seep. This is a good indication that you may get better results, ie better clustering of points into identified seeps, if you increase the vertical search distance in the algorithm.
Points colored by the number of points contributing to the cluster.
Points colored by Accepted status; Accepted status of 0 (colored purple here) indicates that there were not enough points (based on algorithm parameters) to be considered a possible seep.
The Create Cluster Summary tool will produce a new object type titled "Cluster Summary" from the cluster data. This is a standard Fledermaus point object where for each cluster the lowest point in the cluster is selected and added to this object. For seeps this point is likely the closest measured point to where the seep originates and is useful for mapping seeps.
The Export Cluster Information tool is used to export a text file with summary information for the data. This includes : total number of samples; number of clusters found; x, y, z, cluster ID, and number of points in that cluster for each point in a cluster. The XYZ information will be in the projection of the SD file (in the image below, UTM-meters).
The Export Raw XYZ tool is used to export an Ascii file with XYZ locations for all of the points.
The Filter Clusters tool lets you mark the points in clusters as accepted or not based to two types of criterion. The first is simply the number of points in the cluster. In this case if a cluster has the specified or more points in it then all points in that cluster are marked as accepted. For any clusters not meeting the criterion the accepted flag is cleared. You can also filter on the shape of the cluster based on the width to height ratio of the bounding box that encloses all points in a given cluster.
The Delete Filtered Clusters tool this option will delete any points in the object that are not marked as accepted.
The Delete Selected Cluster tool is used in conjunction with the cluster selection slider. If the user chooses a particular cluster selecting this option will remove all the points in that cluster from the object. You can also use the 'd' key to delete the selected cluster as a shortcut.
The Verify Selected Cluster tool allows you to run a test on all the points in the selected cluster. The system will find the nearest point not in the selected cluster to a point in the selected cluster. The test should always pass and it will show the horizontal and vertical distances to that nearest non member point. Note that the system doesn't remember the settings you used to run the clustering from one session to another so if you have just loaded a saved SD file that was clustered with non default ranges and then use this it may generate false test fails. To resolve this run the clustering again with suitable ranges before using this option.
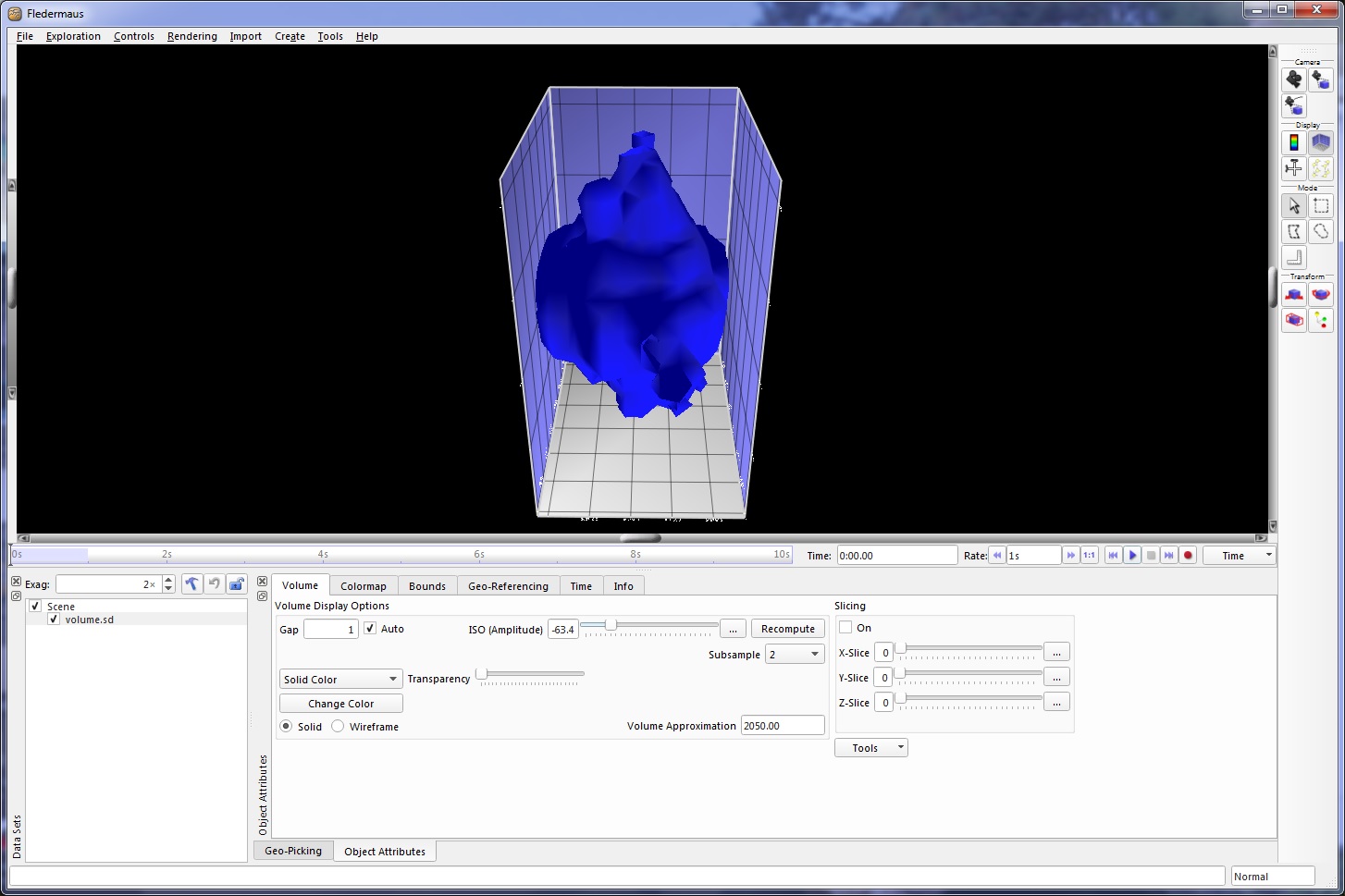
Volume Object
The Volume Object shown in the Volume SD Object figure below is a 3D 'brick' that is divided into 'voxels' of a user-defined size. This brick is grid-aligned and created by ray tracing the instantaneous beam sample position from each filtered ping, beam and sample into the volume. The highest signal level that intersects a voxel is used in the final volume. This volume is then used by Fledermaus to render ISO surfaces based on an ISO level chosen by the user.
The key to generating a good volume object is to have feature data that is spatially coherent and reasonably dense. Good features to export as Volume Objects are fish schools and the plumes detected from seafloor vents. You must choose a proper voxel cell size during export; voxel cell sized is based on your beam spacing and water depth. Cell size is defined on the SD Object Panel shown in the SD Export Panel figure above.